这是之前有一家海外公司招 DevOps 工程师,我投了简历,期望薪资写了薪资范围的最下限,然后被给了份题让先做一下,于是便有了这篇“水”文。
当然,最终我并没有拿到这个 offer,甚至连下一轮见 CTO 的机会都没有。(关于这个,我其实心里还是有一点小小的不服气的。)
题目详情
Q1
写一个定时执行的 Bash 脚本,每月的一号凌晨 1 点对 MongoDB 中 test.user_log 表进行备份、清理,具体要求如下:
- 首先备份上个月的数据,备份完成后打包成.gz文件
- 备份文件通过 sftp 传输到 backup [bakup@bakup.xxx.com] 服务器上,账户已经配置在~/.ssh/config
- 备份完成后,再对备份过的数据进行清理: create_on [2024-01-01 03:33:11]
- 如果脚本执行失败或者异常,则调用
https://monitor.xxx.com/webhook/mongodb - 这个表每日数据量大约在 200w 条, 单条数据未压缩的存储大小约 200B
Q2
根据要求提供一份 Nginx 配置, 要求如下:
- 域名:xxx.com, 支持 https、HTTP/2
- 非 http 请求经过 301 重定向到 https
- 根据 UA 进行判断,如果包含关键字 “Google Bot”, 反向代理到 server_bot[bot.xxx.com] 去处理
- /api/{name} 路径的请求通过 unix sock 发送到本地 php-fpm,文件映射 /www/api/{name}.php
- /api/{name} 路径下需要增加限流设置,只允许每秒 1.5 个请求,超过限制的请求返回 http code 429
- /statics/ 目录下是纯静态文件,需要做一些优化配置
- 其它请求指向目录 /www/xxx/, 查找顺序 index.html –> public/index.html –> /api/index
Q3
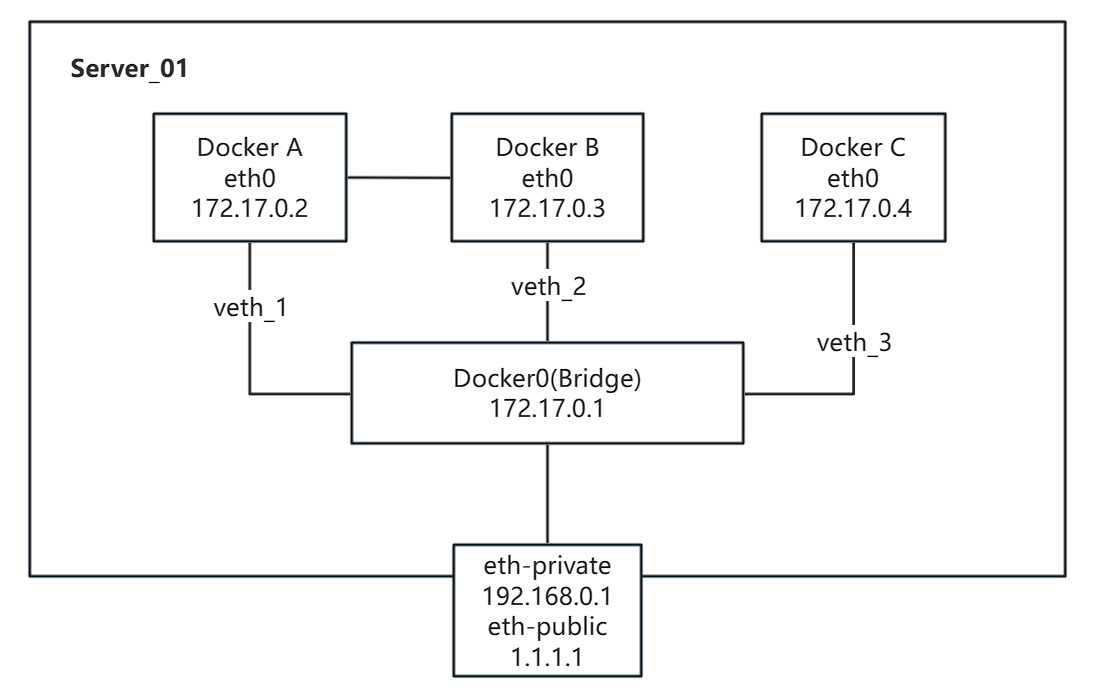
现有一台服务器,如下图所示上面通过默认安装并运行了 3 个 docker 容器,需要通过 iptables 进行网络配置。请给出命令:
- 只有 Docker_A 与 Docker_B 之间可以相互通信,Docker_C 不能访问其它两个容器
- 只允许内网 IP 为 192.168.1.1 - 192.168.1.30 的内网 IP 访问所有容器
- Docker_A:8080 与 Docker_C:80 通过与自身相同端口对外网提供服务, Docker_B:3316 不对外网提供服务
- 所有配置需要固化,重启服务器自动生效
Q4
已知生产环境数据库结构如图所示:
1 | graph LR; |
因为 master 偶尔有硬件问题,需要先将 slave_1 提升为新 master, 然后旧 master 变成 slave_1。请给出操作方案和关键命令。
- 主从数据库服务均处于独立服务器上,有独立的IP;
- 应用程序写入数据库通过域名
mysql-master.xxx.com访问; - 应用程序读取数据通过 Haproxy(
mysql-slave.xxx.com) 访问所有从库01-04 - 尽量平滑处理,不影响生产环境
Q5
在生产环境中,应用程序是通过 Haproxy 来读取 slave 集群,但是偶尔会产生
SQLSTATE[HY000]: General error: 2006 MySQL server has gone away
的错误,请根据经验,给出一排查方案与可能的方向,与开发一起定位问题, 现已经排查:
- 故障发生时,服务器之间防火墙正常,服务器之间可以正常通信;
- 故障SQL均可以正常查询,同时不存在性能问题;
- 故障频率没有发现特别规律,与服务器负载没有正相关;
- 查看各服务的日志,只发现了错误信息,但没有进一步的说明;
1 | graph LR; |
我的答案
A1
如下是备份用的 bash 程序,放在任意合适的目录即可,不过需要记下来路径,cron 的程序 backup_mongo 里要用到,并且给其赋予可执行权限。
1 |
|
如下是 cron 的配置文件 backup_mongo 的内容:
1 | SHELL=/bin/bash |
这个文件请放在目录 /etc/cron.d/ 下
A2
- 如果是 Debian 系的系统,请把文件 ipo.com.conf 放到 /etc/nginx/sites.available/ 目录下并在 /etc/nginx/sites.enable/ 下做一个软链。
- 但如果是红帽系的系统,请把文件 ipo.com.conf 放到目录 /etc/nginx/conf.d/ 下。
以下是文件 xxx.com.conf 的内容:
1 | limit_req_zone $binary_remote_addr zone=api_per_ip:10m rate=90r/m; # 1.5r/s by per IP |
A3
原来给出来的四个需求:
- 只有Docker_A 与 Docker_B 之间可以相互通信,Docker_C 不能访问其它两个容器;
- 只允许内网IP为 192.168.1.1 - 192.168.1.30 的内网IP访问所有容器;
- Docker_A:8080 与 Docker_C:80 通过相同端口对外网提供服务, Docker_B:3316 不对外网提供服务;
- 所有配置需要固化,重启服务器自动生效;
3.1
因为如果不做特殊设置,Docker 容器之间是可以直接互通的,所以这里只需要限制 Docker_C 不能访问 Docker_A 和 Docker_B 即可
1 | iptables -I DOCKER-USER -s 172.17.0.2 -d 172.17.0.4 -j REJECT |
这样设置完毕,反向 172.17.0.4->172.17.0.2 和 172.17.0.4->172.17.0.3 也是不通的,因为回包被拒了。所以反向的 rules 就不用写了。
3.2
第二问有些没太理解,理论上来讲,Docker 容器的网络跟 host 外面是隔离的,无论是 host 上 eth_private 还是 eth_public 上来的流量,应该都是不能直接访问任何容器的。
我只能大概用管饭文档上的一个利子来试着看是不是满足需求:
1 | iptables -I DOCKER-USER -m iprange \ |
3.3
1 | iptables -t filter -A DOCKER -d 172.17.0.2/32 \ |
3.4
这个问题的答案依 Linux 发布版的不同以及具体软件的不同而不同
1 | iptables-save > /etc/iptables/rules.v4 |
A4
这道题我基本上考虑的最多的是怎么样保持数据一致性。系统可用性的考虑反倒是其次。
修改域名解析
- 从域名 mysql-slave.xxx.com 解析,将 slave_1 摘出来
- 尽量将域名 mysql-master.xxx.com 到 master 的指向去掉
逐级设置成 readonly
- 将 master 设置成 readonly(
set global read_only=ON;set global super_read_only=ON;) - 等 slave_1 和 slave_2 的数据跟 master 同步之后(
show slave status里看),将 slave_1 和 slave_2 设置为 readonly - 最后等 slave_3 的数据同步之后,将其也设为 readonly
slave_1 变成 master
- slave_3 从 slave_1 下面拆出来,挂到 slave_2 下面(用命令
STOP SLAVE IO_THREAD;CHANGE MASTER TO slave_2;START SLAVE IO_THREAD) - slave_1 上停掉 slave,起来 master(用命令
stop slave;reset slave all;show master status) - slave_1 上还要启用 replication 的用户
slave_2 挂到 slave_1(new master) 下面
- slave_2 上执行
STOP SLAVE IO_THREAD;CHANGE MASTER TO slave_1;START SLAVE IO_THREAD
master 变成 slave
- master 上执行
reset master; reset slave all; CHANGE MASTER TO slave_1
slave_3 从 slave_2 下拆出来,挂到 master 下面
- slave_3 下执行
STOP SLAVE IO_THREAD;CHANGE MASTER TO master;START SLAVE IO_THREAD
收尾工作:关掉 readonly 并改回域名解析
- 从 slave_1(new master) 开始,逐级关掉 readonly(
set global read_only=OFF;) - 确认数据同步正常之后,修改域名解析:
- 将域名 mysql-slave.xxx.com 将 master(new slave) 加进去
- 将域名 mysql-master.xxx.com 指向 slave_1(new master)
A5
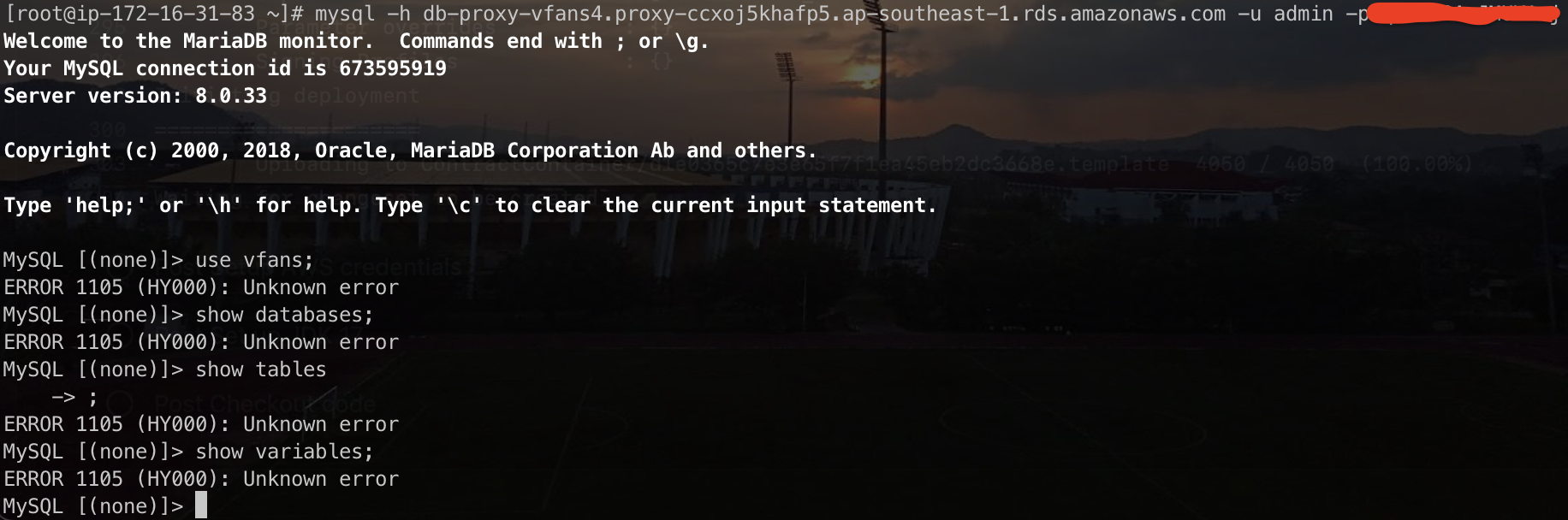
2006 MySQL server has gone away
这个错误的坑我之前刚刚踩过(说是刚刚,其实也是有几个月了),这个错误出现的原因主要就是因为服务器端认为某个连接的 session 超时了,就给强制断掉了,这边客户端不知道,还在傻乎乎的发消息,于是就会得到错误提示:has gone away,控制这种超时的参数有两个:wait_timeout 和 interactive_timeout,但是实际上影响超时的是 session 级别的 wait_timeout 参数。
而 session 级别的 wait_timeout 参数在客户端交互式登录(通常的 MySQL 客户端登录)时,继承的是 global 的 interactive_timeout 参数;而在非交互式登录(比如程序或 jdbc 这种连上来的情况),继承的是 global 级别的 wait_timeout 参数。
所以解决这个问题也有很多办法,最简单的,将这两个参数的值调大。其实这两个参数的缺省值是 8 小时,已经不小了。
要是仅从排错的角度出发的话,那么肯定要 MySQL server 要看日志、HAProxy 要看日志,出错的客户端要看日志,还要在出错的时候看 MySQL server 的状态(show processliss 什么的)
我刚看了有文档说,HAProxy 的 timeout server 和 timeout client 的两个值要跟 MySQL server 上的 session 级的 wait_timeout 一致。
还有,客户端连 HAProxy 的 MySQL 代理时,结束时要显式的主动断开连接。这个我想还好,最怕就是有连接池连 HAProxy 的 MySQL 的代理,我们当时踩坑也是因为有连接池……如果有,大概率是连接池的问题。
总结
我的答案不一定都对,因为我也没有环境去具体测试,但如果这些题是工作中给到我的真实工作内容,我有信心很好的完成他们。
本文由 老杨 原创,转载请注明出处。
]]>